金融界中,数据专家们打造对冲基金预测模型常带有神秘感,既体现了创新与机遇,也潜藏着风险和困难。正因如此,它吸引了众多人的关注。

数据科学家的角色

数据科学家在此环节扮演着至关重要的角色。以Numerai平台为例,美国的数据科学家可以轻松获取到真实的金融数据。他们拥有丰富的专业知识和技能,类似于众多知名研究所培养出来的数据专业人才。2022年,众多数据科学专业的毕业生加入了这一行列。他们通过训练机器学习模型,深入挖掘数据。这项工作并不简单,往往需要投入大量时间,有时甚至长达数月。此外,在构建模型的过程中,他们还需不断调整策略,以应对金融市场的变化。而且,不同数据科学家的思考方式可能截然不同,这也导致了模型之间的差异和多样性。

无论是初学者还是资深的专家,在这个领域,大家都在持续地寻求新知。他们并非只是机械地操作,而是倾注心血去理解数据所蕴含的金融规律。
回归模型

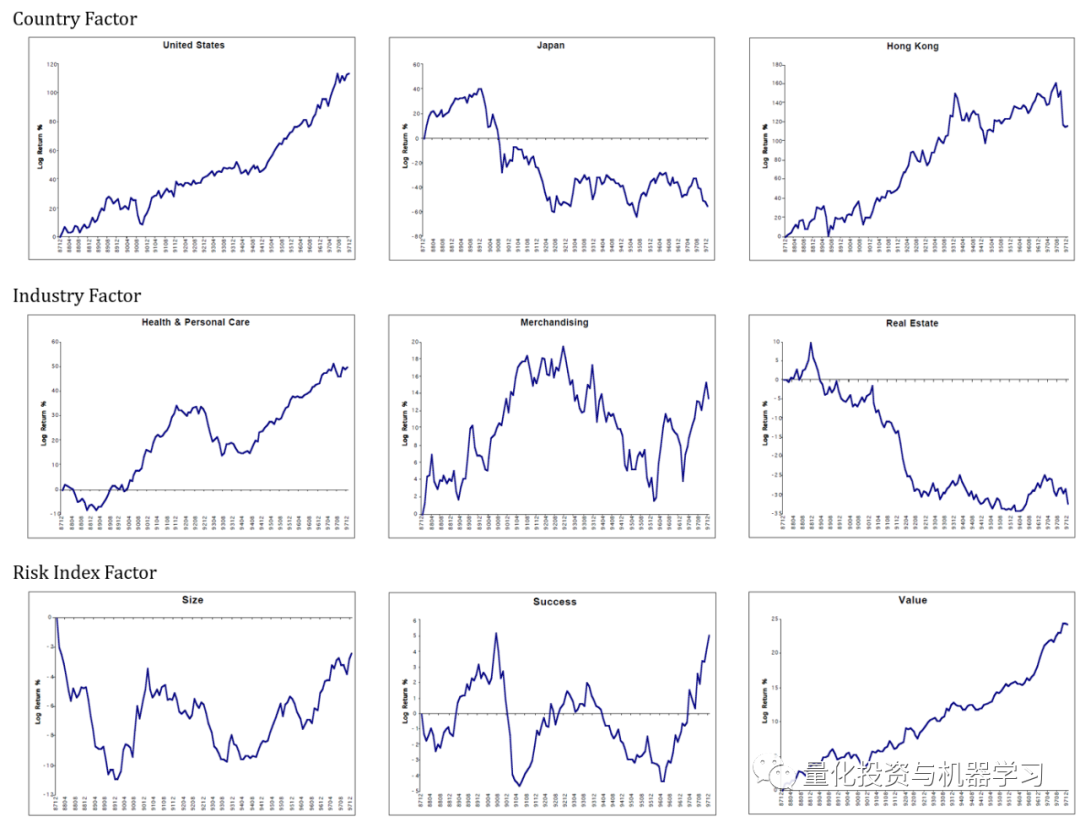
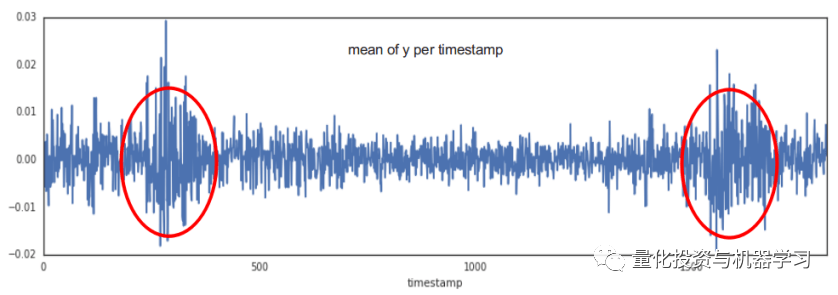
构建预测模型,回归模型是关键一环。以2020至2021年为例,它在那时起到了显著作用。它反映了那个特定时期的状况,我们在月度测试中能观察到其随时间累积的特征。在此过程中,因子收益等同于回归系数,它能将客观和解释变量的波动性转化为关联性。数值的细微变动会直接影响模型的精确度。对量化公司来说,准确计算因子收益至关重要。由于不同地区企业的数据各有差异,比如亚洲与欧洲企业的数据特征不同,因此需要根据不同数据情况,恰当评估因子收益。
此外,对于回归模型的精确度,我们必须结合具体的市场状况进行多次验证。在波动性较大的市场中,因子收益的转换可能会受到干扰,这要求数据专家们必须小心处理。
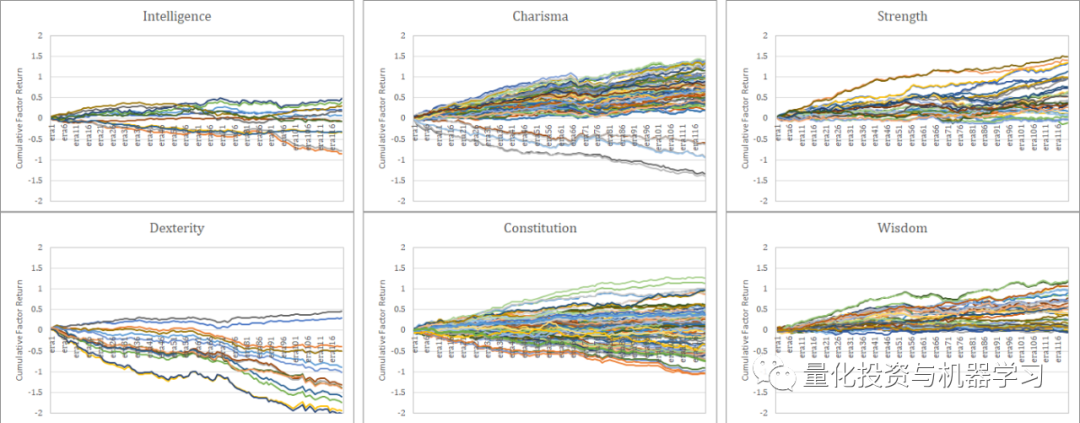
特征构建
参赛者提供的预测属于超因子范畴。在Numerai等平台上,超因子蕴含更丰富的信息。比如,某些队伍运用特殊算法得出的因子。若这些因子表现优异,平台能够灵活运用它们进行组合。以2019年一例成功案例为例,合理搭配多个因子,整体预测效果明显增强。此外,在构建国家特征时,可对各国指数进行多重回归分析。以巴西等新兴经济体和美国等发达经济体为例,它们在回归分析中的表现存在显著差异。beta分位数在此亦扮演不同角色,最高分位数提供关键信息,而其他分位数则信息不足。行业特征同样可通过多元回归贝塔值进行量化。不同行业,如科技行业与传统制造行业,beta分位数的意义也有所不同。
在构建特征时,除了常用的数据,引入替代变量显得尤为重要。比如,分析师对数据的调整或是新闻中的情绪指标,这些都能使特征更加丰富,从而提升预测模型的精确度。
风险模型中的问题
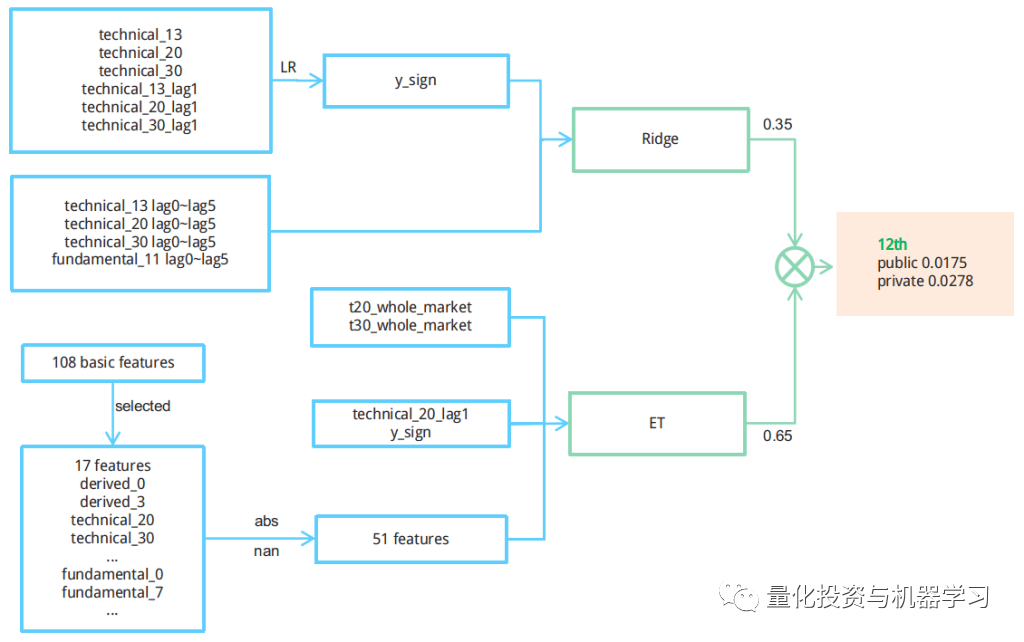
树的模型在解析Barra模型的风险溢价方面有所欠缺。在众多传统量化投资机构中,这种模型因采用网格划分,在处理线性分类问题时往往处于不利地位。2023年的试验案例中,这一问题表现得尤为明显。尽管岭回归模型在预测y信号方面表现尚可,但其数值相对较低。尤其在市场波动加剧时,其回报表现更是受到较大影响。以2008年金融危机为例,即便预测信号准确,回报依然十分有限。在这种情况下,有必要确立新的评估标准。例如,采用动态集成岭回归与ET模型,并利用实际市场动态数据来辅助调整,比如搜集最近5个时间戳的y_mean信号,以使模型能够更准确地判断市场状况。
解决这些问题至关重要,它直接影响到整个对冲基金预测模型的表现。这对数据科学家来说,是必须认真思考的重点因素。
深度因子模型与传统量化投资
在传统的量化投资领域,基金经理通常根据自己的经验来构建和挑选投资因子。以某些知名的基金公司为例,这些公司长期依赖管理人员的个人判断来筛选因子。然而,深度因子模型的目标是利用深度学习技术,替代人工判断,以捕捉单个因子的非线性特征。该模型使用了80个因子来预测月度收益,这一数据是通过多次实验得出的经验值。此外,已有研究证实,深度因子模型在性能上超越了线性模型以及SVR、随机森林等机器学习方法。这一点在相关的研究报告中也有所体现。
然而,深度因子模型的应用并非毫无波折。它需要更多实际案例来验证和优化。并且,它正逐步取代传统方法。
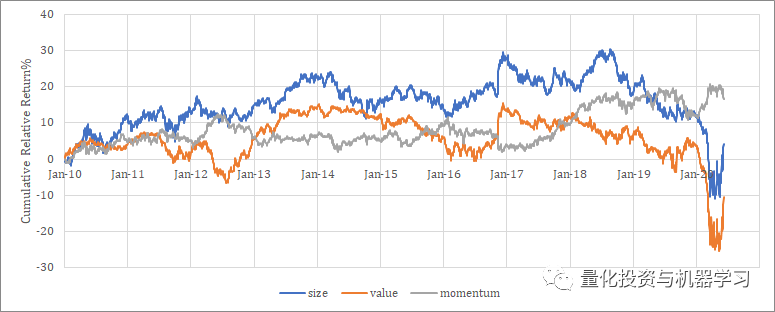
收益模型
深度学习在预测股票收益方面正成为一种新兴趋势。尤其是针对不同因素对股票收益的影响进行预测,比如某些因素对科技股和金融股的影响差异显著。此外,通过应用LRP技术于个股或投资组合,我们能识别出哪些因素对预测有帮助。不同地区的股票市场在这一过程中表现各异。比如,亚洲和欧洲的股票市场,由于市场结构、投资者偏好等方面的差异,对因子分析的反应也各有不同。尽管如此,这一收益模型仍有很大的提升潜力,值得深入研究。
你对数据科学家在构建对冲基金预测模型方面有何独到看法?若有的话,不妨留言交流。同时,也请为这篇文章点赞和转发。